
L’autre jour, pour le compte d’un site qui envoie un flux d’information et de texte à ses partenaires, j’ai eu besoin de vérifier le niveau de duplicate content entre deux pages. J’ai donc utilisé l’algorithme Simhash de Charikar, ce qui m’a permis de comparer les contenus de manière efficace (voir Le secret de Babbar pour calculer la duplication interne).
Avec l’importance croissante de l’optimisation pour les moteurs de recherche (SEO), détecter le contenu dupliqué est devenu primordial. Les moteurs de recherche, comme Google, pénalisent les pages qui proposent un contenu dupliqué, car cela impacte la qualité des résultats de recherche (et il ne sait pas quel est le contenu à afficher). On se retrouve donc à risquer une désindexation parce qu’un autre site a pris nos contenus.
En l’occurrence, les pages correspondaient à la page du site concerné et celle d’un de ses prestataires à qui le client envoyait son contenu. La fonctionnalité de Babbar étant sur la duplication de couple de page en interne, elle ne pouvait pas m’aider dans ce cas. Une fonction similaire pouvait quand même m’aider pour identifier le niveau de duplication.
Petit disclaimer tout de même : il s’agit ici d’identifier, sur des pages que je connais déjà, si le contenu allait être considéré comme dupliqué. Il ne s’agit pas de trouver des pages qui me copient sur le web.
Alors comment j’ai voulu m’y prendre ?
Tout d’abord, j’ai récupéré les urls qui pouvaient être concernées et j’en ai fait des couples d’urls (je ne me suis pas embêté à faire des couples correspondants forcément, j’ai pris la liste des urls du client, celle du site partenaire, et j’ai fait une création de couples d’urls en dehors du même host, le code pour ça est ici : )
import argparse
import pandas as pd
import trafilatura
from urllib.parse import urlparse
import itertools
from simhash import Simhash
def fetch_content(url):
downloaded = trafilatura.fetch_url(url)
return trafilatura.extract(downloaded)
def read_urls(filename):
with open(filename, 'r') as file:
return [line.strip() for line in file if line.strip()]
def create_csv(data, filename):
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
def create_excel(data, filename):
df = pd.DataFrame(data)
df.to_excel(filename, index=False)
def get_features(text):
return text.split()
def text_similarity(text1, text2):
hash1 = Simhash(get_features(text1))
hash2 = Simhash(get_features(text2))
return hash1.distance(hash2)
def main(urltxt):
urls = read_urls(urltxt)
urls_contents = []
for url in urls:
content = fetch_content(url)
host = urlparse(url).hostname
urls_contents.append({'host': host, 'url': url, 'contenu': content})
# Save the URLs with their contents to a CSV file
create_csv(urls_contents, 'urls_categorisees.csv')
# Create URL pairs with different hosts
df = pd.DataFrame(urls_contents)
couples = []
for (i, row1), (j, row2) in itertools.combinations(df.iterrows(), 2):
if row1['host'] != row2['host']:
couples.append({'source': row1['url'], 'target': row2['url']})
# Save the URL pairs to a CSV file
create_csv(couples, 'couples.csv')
# Create an Excel file for the texts
input_texts = [{'identifiant': row['url'], 'texte': row['contenu']} for index, row in df.iterrows()]
create_excel(input_texts, 'input-text.xlsx')
# Compute SimHash distances for the URL pairs
df_couples = pd.DataFrame(couples)
df_couples['simhash_distance'] = pd.Series(dtype=int)
df_texts = pd.DataFrame(input_texts)
for index, row in df_couples.iterrows():
source_url = row['source']
target_url = row['target']
source_text = df_texts[df_texts['identifiant'] == source_url]['texte'].iloc[0]
target_text = df_texts[df_texts['identifiant'] == target_url]['texte'].iloc[0]
distance = text_similarity(source_text, target_text)
df_couples.at[index, 'simhash_distance'] = distance
# Save the updated couples with SimHash distances to the CSV file
df_couples.to_csv('couples.csv', index=False)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Process URLs and compare text similarity using SimHash.")
parser.add_argument('--li', '-list-urls', type=str, required=True, help='Txt file with URL lists.')
args = parser.parse_args()
urltxt = args.li
main(urltxt)Attention, il se peut que vous deviez installer les éléments suivants avant l’exécution du script :
Ajoutez un requirements.txt à votre dossier :
pandas
trafilatura
simhash
argparseet avant d’exploiter le script, assurez vous d’installer les éléments :
pip install -r requirements.txtà utiliser comme suit :
Copiez le code ci-dessus, collez le dans un fichier texte que vous enregistrez sous « nomdufichier.py » (changez le nom du fichier si besoin mais vous devrez alors changer l’équivalent après). Puis créez votre liste d’urls dans VotreListeDUrl.txt (même commentaire sur le nom du fichier que précédemment).
Ouvrez une invite de commande, naviguez jusqu’au dossier sur lequel vous avez vos deux fichiers (python & txt) et entrez cette commande :
python nomdufichier.py --li VotreListeDUrl.txtQue va t il se passer?
Vous allez vous retrouver sur ce dossier avec un nouveau fichier csv : couples.csv. lequel va permettre de constituer des paires de pages, ainsi qu’un autre fichier csv : urls_categorisees.csv qui indique les urls ainsi que les sites sur lesquels elles sont.
Enfin on va créer un fichier Excel input-text.xlsx qui va recenser les contenus des urls, qu’on aura extrait avec trafilatura.
Et à partir de là on a tout ce qu’il faut pour calculer la distance de simhash de ces couples d’urls à partir du contenu extrait via trafilatura. Pour des raisons de sauvegarde de mémoire, on ajoute cette distance dans couples.csv (Attention : distance veut dire que plus la métrique est petite, plus les pages sont proches).
Et voilà !
Liste de questions liées :
Qu’est-ce que la duplication de contenu sur le web et pourquoi est-ce un problème pour les moteurs de recherche tels que Google ?
Le duplicate content, c’est lorsque deux pages ont le même texte, généralement parce que l’un des sites l’a copié depuis l’autre. Cela pose problème à Google, car ces pages renvoient quasiment le même sens, et pour classer les résultats en fonction de leur pertinence sémantique, c’est gênant. Le contenu dupliqué n’est donc pas bien vu par les moteurs de recherche, mais également par les propriétaires de sites, qui risquent de voir une de leurs pages disparaître des résultats de recherche en raison de ce contenu dupliqué.
Comment les moteurs de recherche détectent-ils les pages dupliquées sur internet ?
L’approche de Charikar avec le Simhash est une méthode conçue par Moses Charikar qui utilise une technique de hachage pour identifier le contenu dupliqué sur le web. En 2007, Google a reconnu l’efficacité de cette approche et l’a considérée comme utile pour détecter les contenus dupliqués (source : https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/33026.pdf).
Quel rôle joue Simhash dans la détection de contenu dupliqué en ligne ?
Le Simhash est une fonction de hachage du texte qui permet de réduire le nombre de dimensions considérées dans l’approche vectorielle pour comprendre un texte. C’est une méthode pour simplifier la compréhension des textes et détecter les contenus dupliqués sur le web. Utilisée notamment par les moteurs de recherche tels que Google, elle permet de rechercher les pages similaires ou identiques et de fournir des résultats pertinents aux utilisateurs.
Lorsque les moteurs de recherche effectuent une recherche, ils analysent le contenu des pages à l’aide d’un crawl, qui consiste à parcourir les pages web pour en extraire les informations. Grâce à l’utilisation de Simhash, les moteurs de recherche peuvent détecter les contenus dupliqués de manière efficace, basés sur la fréquence des mots et la comparaison des empreintes digitales des pages. Ils utilisent également des balises comme « rel=canonical » lorsqu’elle est indiquée pour indiquer quelle page est l’originale, évitant ainsi de référencer les contenus dupliqués. Sinon, Google peut produire sa propre balise canonique.
La détection de contenus dupliqués est un problème important dans le domaine du SEO (Search Engine Optimization), car les moteurs de recherche privilégient les contenus originaux et pertinents dans leurs résultats de recherche. Ainsi, les sites qui ont des contenus dupliqués risquent de voir leur classement diminuer dans les résultats de recherche.
Quels sont les outils disponibles pour détecter la duplication de contenu sur les pages web ?
En interne, je peux surtout vous présenter l’outil de Yourtext Guru et Babbar, permettant de mettre en avant un couple de page dupliquée à chaque niveau. Cette fonctionnalité ressemble à ça et est disponible sur les pages suivantes :
https://yourtext.guru/duplicate/host?host=blog.babbar.tech
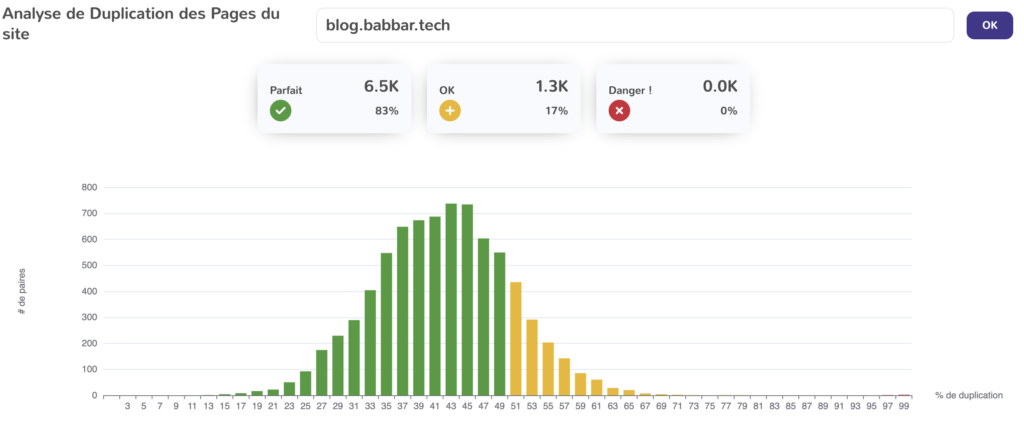
https://www.babbar.tech/host/duplicate/blog.babbar.tech
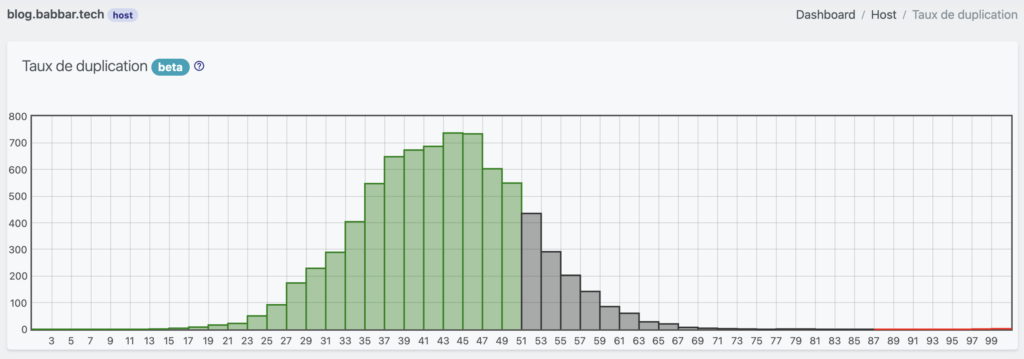
En externe, si vous connaissez les urls, je vous recommande mon approche, sinon d’autres outils qui scannent le web existent pour vous proposer d’identifier les pages qui dupliquent votre contenu.
Quelle est la différence entre la duplication de contenu interne et externe sur un site web ?
La différence se trouve dans l’url qui reprend le contenu : en cas de duplicate content internes, il s’agit généralement de contenu plutôt vides, ou peu modifiés, on connaît surtout le cas sur des pages de produits identiques (sauf pour la couleur par exemple).
En externe, il s’agit d’un site externe qui reprend votre contenu (ou l’inverse).
La différence du point de vue du moteur, c’est qu’en interne, l’une des pages va être facilement considérée comme canonique et finira par être la seule à être mise en avant par Google (après une période d’AB tests de son côté pendant laquelle votre contenu aura des problèmes d’indexations). En externe, les pages concernées risqueront d’être identifiées comme du spam, tout dépendra des pratiques générales du site à la fois sur la sémantique et sur le maillage.
Comment un webmaster peut-il corriger les problèmes de duplication de contenu sur son site ?
Vous pouvez utiliser un outil comme Yourtext Guru pour voir le duplicate content sur votre site et corriger le contenu des pages concernées : il suffit généralement d’ajouter du contenu pour lesdites pages.